

R语言矩阵详解
首先看清题目要求:
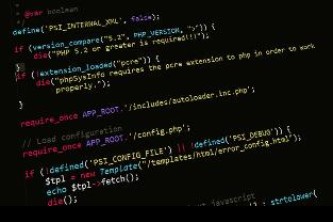
矩阵C是由矩阵A的前3行和前3列构成的矩阵。
分析目的,矩阵A的前3行和前3列到底是多少。
第一步:我们先看矩阵A的数据,箭头所指的就是前3行和前3列的数据。
现在我们已经知道我们所需要的数据是什么。看题目我们可以把第4行和第4、5列去掉,剩下的数据就是我们需要的了。
第二步:就要用到矩阵的其他的函数---矩阵下标。要去掉矩阵中相应的行和(或)列,用负整数我们先把第4行和第5列去掉。
代码如下:A<-matrix(1:20,nrow=4,ncol=5,byrow=FALSE);A<-A[-4,-5]; 已成功去掉第4行和第5列。
接着把去掉一次的矩阵A,再去掉第4列,把去掉的结果赋值给矩阵C,就得到我们想要的矩阵。代码如下。C<-A[,-4]; C
整合全部代码:A<-matrix(1:20,nrow=4,ncol=5,byrow=FALSE);A<-A[-4,-5]; C<-A[,-4]; C
r语言中nr是什么
在R语言中,矩阵(matrix)是将数据按行和列组织数据的一种数据对象,相当于二维数组,可以用于描述二维的数据。与向量相似,矩阵的每个元素都拥有相同的数据类型。通常用列来表示来自不同变量的数据,用行来表示相同的数据。
R语言中创建矩阵的语法格式
在R语言中可以使用matrix()函数来创建矩阵,其语法格式如下:
matrix(data=NA, nrow = 1, ncol = 1, byrow = FALSE, dimnames = NULL)
参数含义如下:
data:矩阵的元素,默认为NA,即未给出元素值的话,各项为NA
nrow:矩阵的行数,默认为1;
ncol:矩阵的列数,默认为1;
byrow:元素是否按行填充,默认按列;
dimnames:以字符型向量表示的行名及列名。
r语言replicate函数的用法
replicate()是R语言中用于重复计算随机数或者试验次数的函数。其基本用法是提供一个参数给n,该参数表示你想复制的次数。该函数将返回一个包含重复结果的矩阵。
以下是replicate()的基本语法:
复制
replicate(n, expr)
其中:
n:表示复制的次数。
expr:一个表达式,可以是任何你想复制的代码或函数。
这是一个简单的示例,用replicate()生成一个长度为10的一维随机数向量:
复制
set.seed(123) # 设置随机数种子以保证结果的可重复性
result <- replicate(10, rnorm(1)) # 生成10个长度为1的随机数向量
print(result)
在这个例子中,我们使用rnorm(1)生成了一个长度为1的随机数向量,然后使用replicate()复制了10次。结果是一个长度为10的一维随机数向量。
注意,如果你需要生成一个二维的随机数矩阵,你可以在expr中使用matrix()函数。例如:
复制
set.seed(123) # 设置随机数种子以保证结果的可重复性
result <- replicate(10, matrix(rnorm(10), ncol=2)) # 生成10个2x5的随机数矩阵
print(result)




还没有评论,来说两句吧...